Yep. We normalize our features as part of training, and the stdevs of each feature are part of the resulting model, along with the weights. (The means are always 0 because of the way we construct our training set.) The weights we use in production are actually normalized_weight / stdev.
You're right, it is begging the question, for any simple function, you basically have to tell it what all the derivatives are for it to work.
The power of this technique is that it handles the product rule and chain rule for you, so composition and multiplication of functions work automatically without extra work.
For the case of 1/(1-x), you only need to tell it the derivatives (wrt x) of
f(x, a) = x * a
g(x, a) = x + a
h(x) = 1/x
Then it automatically knows how to compute the derivatives of h(g(f(x, -1), 1)).
You're right, there's only O(n) information in these particular n x n matrices, so you can multiply them in O(n^2).
The code provided memoizes cell values using the key (r - c), so only O(n^2) work is required to read off the top row of the matrix. I'm planning to make that more explicit in a follow-up post.
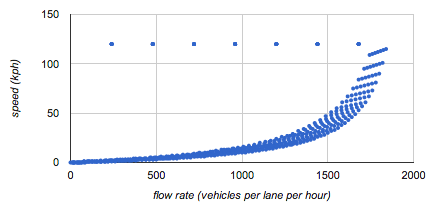
> You can see on the right side how his "cars per second" is _exactly the same_ than on the left side.
Yes, but there are way more cars on the left side. That is the difference. Occupancy (density) determines speed when flow rate is fixed, and that graphic is actually a perfect illustration of this. You can't make the cars on the left travel at 80mph because it would not allow for a safe following distance.
One thing that is the same on both sides is that if you're the nth car back from the merge, it's going to take 2n seconds for you to get to the merge. Yes, the important thing is how many miles you can cover in that time, but this way of thinking places an upper limit on how many miles that can be, based on the occupancy of the road.
Also, pretty sure the advice at the end was tongue-in-cheek ;)
I'm sorry for the harsh critique. I think new radical ideas are great and people should question everything that's out there. But this way was not thought out well enough IMO.
I hope you keep it up and maybe have a follow up post where you can fix some of the flaws.
Some of your ideas are correct and noble. But always remember to take into account the real world driver and his/her behavioral flaws.
Few thoughts: Interesting would be a stochastic behavior model of drivers + driving strategies and in connection with red lights, accidents, rush hour to see what happens. Thought, that model would be quite some work in python.
> I added an update to the article looking at what happens when you vary the average car length (corresponding to the % of trucks on the road), fwiw.
That's silly, at most reasonable traffic flow-rates the difference in a couple of feet between a short car and a long car (esp with how uncommon the outliers are) is insignificant compared to the constant overhead of the per-car padding. And below reasonable traffic flow you're already at a high enough density to cause catastrophic traffic speeds.
OP here. That's a really good point. I just think the original article overreached in saying that zipper merging is a "simple cure" for traffic jams, without taking into account that the road might at or near capacity (and you hit capacity in a hurry when you lose a lane).
My article doesn't account for variance in flow rates in congested traffic, but variance in car length (% of trucks on the road) might explain it. I'm not convinced that merging behavior is the culprit; the original article only speculates that that's the case. I'm putting forward a reasonable explanation for why that isn't the explanation, and a basis for evaluating whether it might be — in particular, whether a zipper merge results in higher flow rates after the bottleneck.
Isn't variance in flow rate the crux of the issue? Merge lanes are a special case in traffic, where another flow is entering the channel. This creates turbulence around the merge point that does not exist where there is pure laminar flow and all lanes can be treated equally. Would it help if "simple cure" was renamed as a "simple improvement?"
Sure, there exists a point where the input flow is great enough that traffic must move slower. OP's entire argument is based off of this. The problem is that there are many things you can do to slow down the flow rate even further, and merging poorly creates this "turbulence" which wastes further flow.
And, it's clear that no improvement in merging behavior can beat the maximum road occupancy, however we can approach that limit much more closely.
I think that conceptually modelling traffic as fluid flows is quite clever, and the "turbulence" idea is particularly satisfying.
{kind=link}
{kind=link}
As for the Control-F thing... stay tuned on that too :)